Understanding Ways of Designing RPA Solutions — UiPath
Robotic Process Automation enables the business to automate manual, high-volume processes by introducing a virtual workforce. The processes that we automate may range from low to high complexity, depending on the business process. Hence, it is important to ensure that the design of the automation solution is easy to manage and scale.

Importance of designing your RPA solution?
Every business process we automate has its own complexity, unique steps, and stages. The suggested solution should also capture the same set of actions to be done automatically. However, automating a process does not mean that you have to follow the same manual steps. There can be different ways of doing the same task when it comes to the technological world. For example, while the user interacts with the interface of an application to perform a specific function, a robot could achieve the same task by:
- Using UI interaction as the user
- Perform API calls to send\ get the required data
- Connect with the database directly to perform the required action
- and many more…
Hence, before the actual development, it is essential to lay down the architecture of the to-be solution. RPA solution design is similar to designing a house. Before laying down the foundation and building the walls, we first need an architect to plan how the house is built according to the customer's requirements. Likewise, in an RPA project, we first need to lay down the foundation for the developers to build the solution.
I have seen scenarios where many start the development without a proper structure in place. It is a very bad practice as it may lead to different complexities and issues over time, such as:
- Difficulty in scaling up the solution
- As the complexity increases, managing a code built without a proper architecture is difficult.
- Introducing new features can be complicated as it may not support the existing structure of the solution.
How Can We Design a Solution?
It does not require extraordinary skills :)
A bit of personal experience:
I, as a Solution Architect, get involved in requirement gathering sessions all the time. As a technical guy, I usually look at converting the business process into a technical flow. As explained before, there could be more than one way of doing the same thing. However, I usually try to relate the process to the Robotic Enterprise Framework (REFramework) and the Dispatcher, Performer concept.
What is the Dispatcher and performer Concept?
The REFramework is designed to process the data as transactions. The framework is by default configured to integrate with Orchestrator Queues to manage the transactions (data) to be processed. The Queues allow us to split the process into multiple subprocesses that enable independent management and scheduling of each subprocess. The Dispatcher is the process that prepares the initial data and pushes it to the following subprocesses to process it. The Performer subprocess retrieves the transaction items from the Orchestrator Queue and processes them one by one by taking into account the business and application exceptions.
Note that both the dispatcher and performer are separate processes designed on REFramework
A business process that is automated end-to-end may contain multiple dispatcher and performer combinations. Further, depending on the business scenario, one dispatcher may provide data to various performer processes. Some of the significant advantages of using this concept are:
- You can easily scale your automation processes.
- The error handling and retrying capabilities can be easily incorporated into the process without much time and effort.
- Considering the overall process, the automation workflows are much simple and less complicated.
Your business process may contain many steps, complex business rules, complex data processing activities, and handover points between subprocesses. However, mapping everything into the dispatcher-performer concept may differ based on the scenario. We will discuss a few other methods later in the article.
It is important to identify the handover points and break the complex business process into multiple simple automation processes that connect through data handover features such as Queues, Data Tables, etc.
To understand this concept better, let’s consider the following business case.
- A business user downloads a set of reports from two ERP applications
- The downloaded data is processed and cleansed
- Cleansed data is sent to specific users through email.
- The receiver updates the file and replies to the business user
- The business user validates each received email.
- If any error is found, he replies to the email asking for a correction. If the data received is valid, the information is updated in another downstream application.
If you are asked to provide a solution design for the above scenario, how would you categorize each step into the dispatcher-performer concept?
Answer:
If you think about the steps, the process is quite complex and consists of many repeat stages and may even lead to retries in case of an error. Hence, including everything in one REFramework solution is not possible. However, if you break it down into the dispatcher-performer concept, you will get a few subprocesses. You will be amazed to see how easy the task performed in each subprocess is.
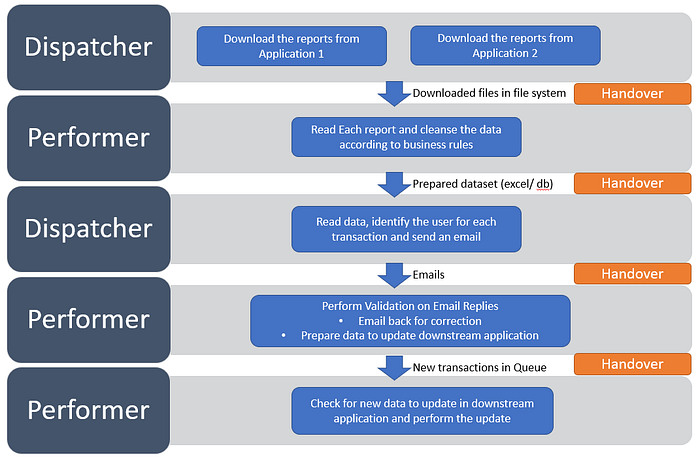
As shown in the figure, we have several dispatcher and performer processes for the entire process. Further, if you closely look, the second performer process (perform validation on email replies) acts as the “performer” for its dispatcher and as a “dispatcher” for the last performer process.
What factors should be considered to split the process, as shown above?
We can look at a few elements of the process:
- What you get as input data
- Out of all the input data, what dataset can act as the master dataset that refers to other input data? (This means we need to identify the main dataset that we can use as a reference to connect with all other data points, For example, the list of file paths in a folder to access data elements in each file)
- What applications do you need to access to obtain the input data
- If applications are involved, at what point/ screen you will be extracting the information, and what steps are carried out to get to that screen
- Do you need to perform any additional actions to retrieve the data?
- What are the business rules and application exceptions that you may encounter?
- Once you retrieve the required information, what do you do next?
- Do you process the data as individual transactions, or do you process it as a bulk?
- When you process each data element, what conditions do you check? (business rules and application-related scenarios)
- Once the data is processed, what is the output that you generate from the process?
- What data is required to generate the required output
Based on the information you capture on the above questions, try including it in the following diagram.
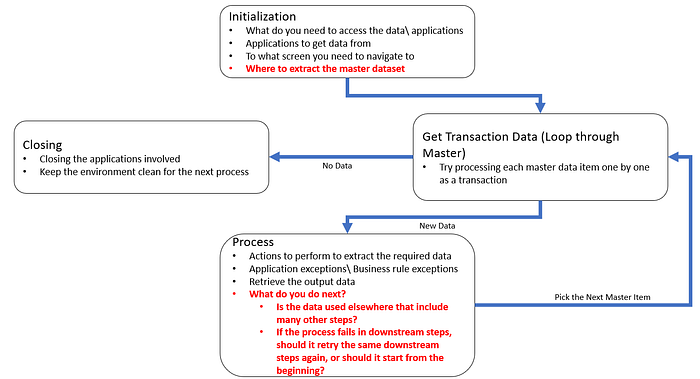
It is important to figure out the main dataset as it is the starting point of the entire process. The main dataset could depend based on the process. However, it should ideally be:
- An excel file that contains the initial data points that help us dig into the details
- Windows file system (file paths/ folder paths)
- An application in which we need to download the main dataset.
Once you identify the starting point, try mapping how the rest of the actions\ steps fall into the sequence until you derive the required output from that input.
Always ensure to use the REFramework to automate your processes. Do not overcomplicate the process. Find points where you can split the process into multiple sub REFramework solutions.
Do we always need to use the REFramework?
You might wonder why to use REFramework all the time, even if the process is sequential and linear. Let’s have a look at the following example.

As stated in the previous example, we are supposed to download a report from Application 1. The following are the steps:
- Login to Application 1
- Navigate to the required page
- Provide the input values needed to generate the required report
- Hit on download to download the report
As mentioned above, the set of steps look sequential and do not have any transaction items. The steps in the process are executed only once. So why do we need REFramework?
Answer:
We, as developers, always need to consider the fact that exceptions can occur even on a smooth workflow. These exceptions could be data-related or application-related. For example, let’s assume the internet got cut off while the process is running for a couple of seconds. The process should ideally identify the issue and automatically try to restart from the beginning to check whether it can overcome the issue by itself.
Let’s look at another example. Let’s assume that the robot is trying to provide an email address that is not valid and was provided by the user in the configuration by mistake. Instead of throwing the error, the robot should log the error in a meaningful way and gracefully end the process.
If we do not use the REFramework, we will need to build the same exception handling procedures ourselves. The REFramework includes pre-built exception handling that increases the reliability of the process. Hence it is always a good practice to have the steps of the process in a REFramework solution even though the process is linear.
The REFramework is highly customizable. You can easily change it to work as a linear process by fixing how it navigates between transactions.
Now let’s see how we can place the above-stated steps in a linear REFramework solution. Try mapping it into the key elements I mentioned earlier and follow the below diagram.
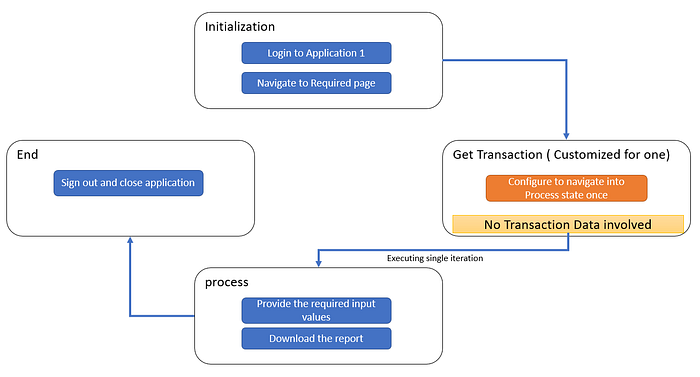
The diagram above states how we can include the set of steps into the REFramework easily.
We now know how the dispatcher-performer concept and REFramework support architecting any (complex or linear) RPA solution. We have one more thing to discuss…
Is it always mandatory to use the dispatcher-performer concept? Even for a simple process?
As mentioned above, the use of REFramework is a good practice for any complex or linear process. However, the need for the dispatcher-performer concept may depend on the process complexity. If the process is complicated, we need to go for the dispatcher-performer concept as the example given above.
Let’s think of a straightforward process done by most of the HR teams in any company.
The HR team needs to regularize the employees' attendance before the end of the month to perform the payroll process. Let’s assume that they conduct the following steps to complete this process.
- Log in to the HR system.
- Extract Employee list
- Identify the employees that need to regularize their attendance
- Send out an email to the employee asking to regularize their attendance
If we have a close look at the process, the steps are straightforward. We can efficiently perform the same actions within one REFramework solution using the employee as the transaction item. Hence, if we design the stated process, it would look similar to the following diagram.
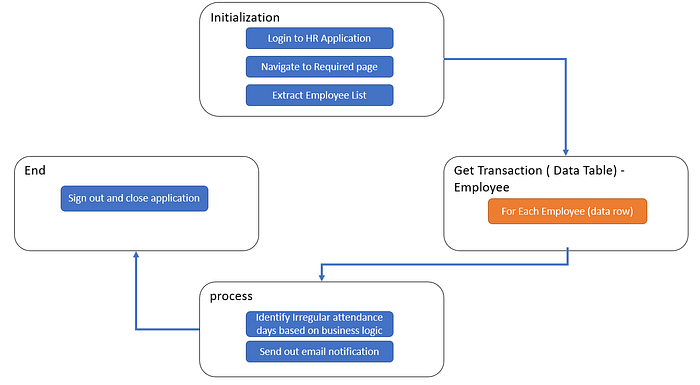
In this scenario, we can easily customize the REFramework to use a Data Row as the transaction item and perform the actions within the single framework itself. Hence, in this scenario, we don’t need to go for the dispatcher-performer concept. But, you can see how easy it is to use the REFramework to design the process.
Concluding…
As we discussed, RPA solutions may range from sequential to complex automation solutions. However, try to capture the key data elements required to design the solution and always try to map it to the REFramework and\or dispatcher-performer concept. By doing that, we can easily create a robust, efficient, and reliable solution.
Keep in mind not to directly go into development. Always lay down your points, draw them in a REFramework diagram in the most detailed level.
Granular the design is; easy to design and understand the process.
